| QUOTE |
| ვერ ცნობს ტექსტს სრულად და იეროგლიფებს წერს ზოგ სიტყვაზე და ასოზე |
მე ჩემი ქართულის წიგნი დავასკანერე და 99% შედეგი მომცა .
 ხელით დაწერილს ვერა, მარა ნაბეჭდს კი ...
ხელით დაწერილს ვერა, მარა ნაბეჭდს კი ... | Printable Version of Topic
Click here to view this topic in its original format |
| თბილისის ფორუმი > Georgianisation > OCR ქართული ოპტიკური ამოცნობის სისტემა SunnyPage |
| Posted by: daylight 1 Jun 2012, 16:45 |
| OCR ქართული ოპტიკური ამოცნობის სისტემა SunnyPage v1.1 ბოლო განახლებაში ცვლილებები შეეხო ქართული ენის ამოცნობას ფასი: სულ 45 ლარი ქართული ვერსია 140MB http://www.sunnypage.ge/ge ერთი დღე უფასო გამოყენების ვადა |
| Posted by: Accident 1 Jun 2012, 16:50 |
| daylight იქით გკითხეს რაღაც http://forum.ge/?f=32&showtopic=34396163 |
| Posted by: koba71786 5 Jun 2012, 13:46 |
| ვერ ცნობს ტექსტს სრულად და იეროგლიფებს წერს ზოგ სიტყვაზე და ასოზე |
| Posted by: Yan-LoonG 5 Jun 2012, 15:17 | ||
მე ჩემი ქართულის წიგნი დავასკანერე და 99% შედეგი მომცა . ხელით დაწერილს ვერა, მარა ნაბეჭდს კი ... |
| Posted by: koba71786 5 Jun 2012, 15:47 |
| Yan-LoonG რა ფორმატი იყო ის წიგნი? პდფ? არა მე წიგნები არ მიცდია,აი მაგალითად აქ ფორუმზე გადავუღე სურათი და ის დავასკანირე. აი ნახე თუ გინდა  |
| Posted by: Power_VANO 5 Jun 2012, 16:00 |
| koba71786 სკრინშოტი არის 72 DPI, რაც არანაირად არაა საკმარისი OCR-სთვის. OCR-ს კარგი შედეგისთვის უნდა 300 DPI |
| Posted by: koba71786 5 Jun 2012, 16:02 |
| Power_VANO რა არის ეგ DPI? მაშინ როგორ უნდა გავაკეთო რომ სქრინშოტიდან ან მაგალითად პდფ წიგნიდან სადაც სურათებითაა ეს წიგნი,რომ ამოიცნოს ამ პროგრამამ,რომ გადაიყვანოს ტექსტში |
| Posted by: Power_VANO 5 Jun 2012, 16:33 |
| koba71786 DPI = Dots Per Inch ანუ წერტილების რაოდენობა კვადრატულ დუიმზე. დაასკანირე ფურცელი და მიუთითე Resolution-ში 300 DPI. |
| Posted by: koba71786 5 Jun 2012, 17:09 | ||
Power_VANO
ეგ ამ პროგრამაში უნდა გავაკეთო? |
| Posted by: Accident 5 Jun 2012, 17:37 | ||
koba71786
რა ამ პროგრამაში?! სკანერი უნდა გქონდეს. http://www.hotspot.ge/scanners/c920/ |
| Posted by: koba71786 5 Jun 2012, 20:22 | ||
Accident
 ხოო მე კიდე პროგრამაში მეგონა. |
| Posted by: daylight 5 Jun 2012, 20:30 |
| ფოტოაპარატით შეიძლება, თუ 5M Pixel-ი არის ან მეტი, მობილური კამერა ცუდ შედეგს მოგცემს. ოღონდ ზუსტად უნდა გადაუღო, შორიდან ან დახრილად არ უნდა იყოს. * * * ოღონდ ეკრანი არ გადაიღო ფოტოაპარატით. (ვხუმრობ) |
| Posted by: koba71786 5 Jun 2012, 22:59 | ||
daylight
ოკ.გასაგებია |
| Posted by: დელფი 18 Jun 2012, 18:00 |
| daylight PM ნახეთ, თუ შეიძლება. |
| Posted by: დელფი 26 Jun 2012, 12:40 |
| რამდენიმე დღეა ვსარგებლობ ამ პროგრამით და ძალიან კმაყოფილი ვარ! მშვენივრად ახდენს დასკანრებეული ტექსტის ამოცნობას! მადლობა ავტორებს ამ დიდებული პროგრამისათვის! |
| Posted by: dato198613 25 Aug 2012, 01:46 |
| და არსებობს რამე ხერხი რო ხელნაწერის ამოცნობა რო შეძლოს? ან ისეთი ფონტის რაც ჩამატებული არ არის? |
| Posted by: Yan-LoonG 28 Aug 2012, 11:20 | ||
ხელნაწერსაც გააჩნია, თუ დაჯღაპნილია ასოები გადბმულია და პატრონის გარდა ვერავინ კითხულობს ვერ ამოიცნობსდა თუ მაქსიმალურად არის მიმსგავსებული Sylfaen -ის ასოებს, ანუ ეხლა რასაც ვიყენებ მაშინ ამოიცნობს. |
| Posted by: parole 18 Oct 2012, 15:13 |
| ძაან კარგი და ერთობ საჭირო რამეა ეგ........... მივესალმები!!! -საინტერესოა - რა ჯდება ეგ სიამოვნება? |
| Posted by: Bluetooth_a 14 Nov 2012, 21:35 |
| ერთი და იგივე .pdf და .bmp ვცადე არ გადაიყვანა  |
| Posted by: basa-ttt 18 Dec 2012, 23:03 |
| მე გადმოვწერე ახლა საცდელი ვერსია და ძალიან ნელა მიდის ტექსტის ამოცნობა... რატომ??? |
| Posted by: Chincha 26 Jan 2013, 15:36 |
| მეც გადმოვწერე ეს პროგრამა დაინსტალირდა უპრობლემოდ რაც შეეხება მუშაობას სამწუხაროდ ბევრია წუნი პროცენტულად იმდენია რომ წიგნის გადატანა აზრს კარგავს ამ პროგრამით პრობლემაა შენახვაზე შედარებით ახალი ტექსტები ასე თუ უსე იკითხება ძველ წიგნზე რაც მე მაინტერესებს უფრო მეტად აშკარად უჭირს მეორე არ მომწონს 1 დღე ეს ძაან მცირე დროა მივწერე წერილი ავტორებს პასუხი იყი ცოტა გაუგებარი ტავიდან გვქონდა 2 კვირა მარა ამ პროგრამის გამო ყოველ ორ კვირაში ვინდოუს თავიდან აყენებდნენ მომხმარებლები და ამიტომ 1 დღე პროგრამა საჭიროა და მისასალმებელია მაგრამ სამუშაოა კიდევ ბევრი რადგან მუშაობის ხარისხი თუნდაც უფასო ამომცნობ პროგრამებთან არის დაბალი |
| Posted by: daylight 26 Jan 2013, 18:36 |
| აღნიშნული პროგრამის ვერსია არის ძველი, სულ მალე ვაპირებთ გამოვუშვათ ახალი ვერსია, დაახლოებით 10-15 დღეში. ახალ ვერსიაში დაემატება ცხრილების ამოცნობა. ასევე გაუმჯობესდება პუნქტუაციის ნიშნების ამოცნობა. |
| Posted by: Chincha 28 Jan 2013, 19:25 | ||
კარგია რომ ფიქრობთ გაუმჯობესებაზე პროგრამაზე საჭიროა მუშაობა ნამდვილად საჭიროა ქართული ამომცნობი ახლა კი რეალობა ასეთია http://radikal.ru/F/s018.radikal.ru/i523/1301/43/95aaa401fdfe.jpg.html http://radikal.ru/F/s019.radikal.ru/i643/1301/44/473dbb69199c.jpg.html * * * http://s019.radikal.ru/i643/1301/44/473dbb69199c.jpg |
| Posted by: -Alex- 19 Feb 2013, 02:41 |
| Chincha სხვა OCR ნახე შენ. მე ძალიან გამაკვირვა ამ პროგრამამ შედეგით. საუკეთესო ძრავზე მუშაობს რაც არსებობს. მოკლედ წარმატებები სანის |
| Posted by: თერალ ი 30 Mar 2013, 20:04 |
| გადმოვწერე საინსტალაციო ვერსია, მაგრამ ინსტალაციის ბოლოს დამიწერა ვინდოუსის ამ ვერსიაზე არ წავაო. http://www.radikal.ru მიყენია ვინდოუს XP რუსული რა ვქნა ? |
| Posted by: Accident 30 Mar 2013, 20:57 | ||
თერალ ი
არ ყენდება xp-ზე სხვები სცადე http://forum.ge/?showtopic=33690429&view=findpost&p=32375152 |
| Posted by: HCl 10 Apr 2013, 01:24 |
| ეს გამოვიყენე ტრიალი და ძაან ამგრად მუშაობს მადლობა შემქნელებს |
| Posted by: EMOziko 14 May 2013, 16:32 |
| დომენი გაუქმებულია და სად შემიძლია რომ ეს პროგრამა ვნახო? |
| Posted by: daylight 15 May 2013, 11:44 |
| სხვა ხოსტინგზე გადავედით და რამოდენიმე დღეში ჩაირთვება. |
| Posted by: fаshist 2 Sep 2013, 23:43 |
| დავაყენე ყველაზე კარგად მემგონი ეს პროგრამა მუშაობს თუმცა მინუსებიც აქვს 300DPI-ში დასკანირებული 90% სწორად აღიქვა ხოლო 600-ში პირიქით გაუჭირდა და ალბათ 70% დაინახა სწორად დანარჩენი სულ ციფრები წერია სიტყვების ნაცვლად კიდე მაგალითად ა982399 აი ასეთი რამ თუ წერია ა-ს ვერ ხედავს და ციფრად აღიქვამს და ასევე ძალიან კარგი იქნებოდა ფაინრიდერივით რომ იყოს გადაყვანილ ტექსტს რო მონიშნავ და ქვემოთ სურათზე განახებდეს რა ადგილს ნიშნავ (ადვილად რომ შეატყო სწორად გადაიყვანა თუ არა) |
| Posted by: daylight 16 Apr 2014, 12:58 |
| გამოვიდა ახალი ვერსია SunnyPage 2.1, ხუცური ენის მხარდაჭერით, განახლებული შესწავლის პროცესით და განახლებული ქართული ენის მონაცემთა ბაზით: http://www.sunnypage.ge/ge/ |
| Posted by: PagSoft 16 Apr 2014, 15:16 |
| daylight სასვენი ნიშნების სწორად ამოცნობის მხრივ წინსვლა არის? |
| Posted by: daylight 16 Apr 2014, 16:52 |
| წინსვლა არის...________________ |
| Posted by: შაქროII 16 Apr 2014, 23:48 |
| ჩამოვქაჩე ვერსია. 1.დეფაულტ დირექტორიის სახელში როცა დაყენებას იწყებს არის ვერსიის სახელიც სადაც ფიგურირებს მძიმე. პრობლემა არაა მაგრამ მაინც რომ შეასწოროთ ჯობია. 2. დაყენება რომ დაიწყო ვერ გავიგე გაჭედა თუ მუშაობდა და გაუქმებაზე დავაწკაპუნე. 3. ისევ ვერ გავიგე გაჭედა თუ არა. 4. მოვკალი ტასკ მენეჯერიდან 5. გამოვრთე ავასტი. 6. დავიწყე ტავიდან. 7. ნაწილი დაუყენებია დ ამოდიფიცირება მომთხოვა. 8. დავეტანხმე და დადგა 1 ძველი წიგნია 50იანი წლების...ყვითელი ფურცლებით . ზოგან ჩაბნელებულია ზოგან არა. 300დპაი ხარისხით. შევუშვი 1 დასკანირებული სურათი (2 გვერდია ერთად). შენიშვნებში ქვემოთ არის რუსული ტექსტიც. შედეგი: რუსული ვერ ამოიცნო ქართული ამოიცნო 90% სწორად. შეფასება: +მშვენიერია... ძალიან კარგია.... + იცნობს კარგად...ეხლა ყავას ვერ მოადუღებს და ვებპეიჯად ვერ აქცევს დასკანირებულ ჯპგ-ს -ინსტალატორი ცოტა უფრო ინფორმატიული გახადეთ მაგ ტექსტური ინფოები რომ იყოს: "ვხსნი არქივს" "ვაკოპირებ ფაილს კკკ.დლლ -ს" -ანა რ აქვს ან მე ვერ ვნახე როგორ ამოვაცნობინო მრავალ ენოვანი. მაგ ქართული+ინგლისური+რუსული ტექსტი? "შესრულებულია 10% მაითმინე ჯიგარ!!" დემოს რა შეზღუდვები აქვს? სად შეიძლება ყიდვა? ასეთ პროგისთვის მით უმეეტს ჩვენების შექმნილისთვის არ დამენანება არც 45 არც 100ლ გისურვებთ წარმატებებს პ.ს. თუ საიდუმლო არაა პიქსელ პიქსელ ადარებთ უკვე ცნობილ გლისფებს თუ რაიმე ლოგიკური ალგორითმს იყენებთ? /მაგ. ლაბირინთის ალგორითმის მსგავსი/ ...პ.ს. რუსულიც ჩავურთე და 70% ამოიცნო.... კარგია ... |
| Posted by: DrAcid 16 Apr 2014, 23:59 |
| შაქროII იყენებენ Google Tesseract OCR ძრავს, თუ სწორად მახსოვს... ცალკე ძრავის დაწერა საინტერესო იქნებოდა |
| Posted by: შაქროII 17 Apr 2014, 00:46 |
| DrAcid ჰო საინტერესო იქნებოდა.... ......................ინსტალლერის 5 ზომბი პროცესია დარჩენილი პროგრამის დახურვის მერე რომელსაც ტასკმენეჯერიც ვერ კლავს  .... ....მოკლედ ინსტალლერს სჭირდება მეტი მუშაობა |
| Posted by: daylight 17 Apr 2014, 12:54 | ||
არ გადაასწოროთ მძიმე წერტილზე, პროგრამაში შესწავლის პროცეს სჭირდება მძიმე. |
| Posted by: Dixtosa 17 Apr 2014, 15:27 | ||
უფრო უაზრო მაგის ცოდნა, დრო და მონდომება აქვს ვინმეს :? |
| Posted by: shoshia 17 Apr 2014, 18:26 |
| Dixtosa ცოდნა რატომ ინებოდა უაზრო თუ უკეთესი ალგორითმით უფრო სწარაფად მოხდება ტექსტის ამოცნობა? 2-3 გვერდს არაუშავს გინდ 10 წუთი დაგიხარჯავს გინდ 15. მაგრამ 200-300 გვერდზე უკვე დიდი განსხვავებაა. |
| Posted by: Dixtosa 17 Apr 2014, 18:59 | ||
shoshia
უფრო უაზროს მერე წერტილი ვიგულისხმე |
| Posted by: shoshia 17 Apr 2014, 19:33 |
| როოგორ მუშაობს აზრზე არ ვარ მაგრამ თუ ვიცი კვადრატი სადაც გლიფია. რა ასო ნიშნანი წერია ამ კვადრატში 100% ამოვიცნობ . პუნქტუაციას და რიცხვებს კი ინგლისურის ამომცნობი მოდულიდან ავიღებ ...ასეთი ღია წყაროს ბიბლიოთეკა თუ ვნახე...მოკლედ შესწავლა უნდა..ამ ზაფხულს ვაპირებ მაგაზე ჩაჯდომას |
| Posted by: DrAcid 17 Apr 2014, 20:21 |
| Dixtosa რატომ უაზრო? მანქანური სწავლების ერთ-ერთი განხრაა, რომელიც მოიხმარება ობიექტების ამოცნობა ვიზუალური გამოსახულებიდან, ოღონდ ამ შემთხვევაში მოიხმარება სიმბოლოების ამოცნობისთვის. მშვენიერი (ვთქვათ) სამაგისტრო ნაშრომის დაწერა შეიძლება, ან უბრალოდ საინტერესო კვლევის გაკეთება. აქ ხომ ძალიან ბევრი ასპექტია:
ეს არის სულ მცირე, რაც უცებ მომაფიქრდა. ჩემი აზრით კოლოსალურად საინტერესო საქმეა, მთავარია ადამიანს დრო და ინტერესი ჰქონდეს * * * shoshia Tesseract OCR არის თავისფალი და ღია წყაროს მქონე: https://code.google.com/p/tesseract-ocr/ |
| Posted by: Dixtosa 17 Apr 2014, 23:44 |
| DrAcid სხვისი არ ვიცი მარა ველოსიპედს თავიდან არ ვიგონებ ხოლმე. თან მითუმეტეს როცა საბოლოო ჯამში ველოსიპედი კი არა უბორბლო დალეწილი "ტრანგალეტკა" იქნება არამგონია tesseract-ზე კაი გამო(მი/უ)ვიდეს. პ.ს. არ ვიცი როგორია tesseract მარა გუგლი ურევია სახელში და ალბათ კაი იქნება |
| Posted by: Accident 17 Apr 2014, 23:48 | ||
საგონებელი რაღაა, ხომ ფაქტია, რომ გამოუვიდა, თემის ავტორს......... |
| Posted by: შაქროII 18 Apr 2014, 02:07 | ||||
DrAcid
მე რასაც ვფიქრობ ხაზგადასმული იქნება რთული . ორ ტესტში დავადგენ ასოს . ხაზგადასმული ასოებინაბეჭდ ან ხელნაწერში დიდი იშვიათობაა
ასევე დაამატე შებრუნებული შემტხვევა ანუ ლიგატურები როცა ორ ან მეტი ასო გადაბმულია.Dixtosa ფონტებით სწავლებას თუ ავიღებთ მართლი ხარ..მაგარმ ნახავ რომ მაგ მიდგომით გაკეტებული პრგრამა რომელსაც სურს რომ იყოს კომერციული და მაგარი და თიტქმის 100% შედეგის და ა.შ. იქნება და არის ძალიან დიდი.1 ენისთვის არაუშავს. ამას გარდა უამრავი ძველი წიგნია რომლესაც ასკანერებენ მაგ. იგივე არხივ.ორგ ან გუგლი. სხვადასხვა უნივები და ა.შ. 2 ჯერ სწარად რომ იმუშაოს პროგრამა ნიშნავს 2ჯერ მეტი საქმის გაკეთებას იგივე დროში და ორჯერ ნაკლებ ხარჯს --დაქირავებულის ხელფასს რომელიც ასკანერებს.თუ თვენი ამოცანაა ამომცნობი პროგრამის დაწერა ეს 1 ამოცანაა თუ უკეთესი სწრაფი ალგორითმის მოფიქრება და პროგრამული კოდის შექმნა ეს მეორე ამოცანაა. ფონტებიტ და პიქსებებიტ დასწავლა უფრო უნივერსალურია იმ გაგებით რომ ყველას შეუძლია ასწავლოს ყველა ენისთვის.... სხვა ალგორითმს დასჭირდება სხვადასხვა ალგორითმი/ მოდული/კოდი სხვადასხვა ენისთვის..პროგრამულად უფრო რთულია....მაგრამ დაიკავებს ნაკლებ ადგილს დისკზე და ამოცნობას დასჭირდება ნაკლები დრო. |
| Posted by: DrAcid 18 Apr 2014, 04:54 | ||||
| Dixtosa ველოსიპედის გამოგონებას ვინ ითხოვს? აიღე არსებული პუბლიკაციები ამ თემაზე, გაეცანი და შექმენი შენი ალგორითმი. შეიძლება სხვაზე უფრო ზუსტი იყოს, მაგრამ ნელი, ან პირიქით არადა საკმაოდ ცუდი ძრავია tesseract, ბევრთან შედარებისას აგებს, თუ სწორად მახსოვს. აგერ, დაწვრილებითი კვლევა თუ გაინტერესებს: http://lib.psnc.pl/Content/358/PSNC_Tesseract-FineReader-report.pdf შაქროII
გეთანხმები თუმცა უკეთესი და სწრაფი ალგორითმის მოფიქრებისთვის ჯერ სხვები უნდა იცოდე და გქონდეს გაკეთებული, უნდა ერკვეოდე მათ ნიუანსებში და bottle-neck-ებში.რაც არ უნდა იყოს, არაჩვეულებრივად საინტერესო პროცესი უნდა იყოს.
ძირითადად ამისთვის წერენ OCR-ებს. თან ვიცი ხალხი აწყობს წიგნების სპეციალურ სკანერებს, რომლებიც წიგნებზეა გათვლილი, თვითონ ფურცლავს, ორივე გვერდს ასკანერებს, კუთხის ფორმა აქვს წამკითხველს და ა.შ. |
| Posted by: CDMA 18 Apr 2014, 09:42 |
| საინტერესოა, მესიამოვნა რომ ვიღაცა რაღაცას კიდე აკეთებს. ერთი კითხვა მაქვს,უკვე დაისვა მაგრამ მაინც. რა "ძრავა" -ზეა ეს პროგრამა აწყობილი? მე მაქვს ჩემით გაკეთებული დასრულებული ალგორითმი, რომელიც მორგებულია კონკრეტულად ქართულ შრიფტზე, ნაბეჭდ ტექსტზე ფანტასტიკურ შედეგს იძლევა მაგრამ კოდი როგორც ასეთი არაა ბოლომდე მიყვანილი. მამენტ თუ ეროვნული საქმე კეთდება, გავცემდი ჩემ ალგორითმს... |
| Posted by: EMOziko 18 Apr 2014, 13:24 |
| ტესერაქტი მაგარი ძრავაა და არამგონია დიდი აზრი იყოს ახალი ძრავის შექმნაში. მითუმეტეს, როცა ის ღია კოდისაა და ყველას შეუძლია ცვლილების შეტანა. მე პირადად გავაკეთე ქართულის ბიბლიოთეკა (სხვანაირად არ ვიცი როგორ ვუწოდო) ტესერაქტისთვის და მშვენივრად იმუშავა. ძალიან დიდი ფუნქციონალი აქვს ძრავას, მარჯვნიდან-მარცხნივ მიმართული და ვერტიკალური დამწერლობების მხარდაჭერაც აქვს. ნებისმიერ ტექსტს აღაქმევინებ მონდომების შემთხვევაში |
| Posted by: DrAcid 21 Apr 2014, 05:29 | ||||
CDMA
+1  მაგარია ბენჩმარეკები ხომ არ გაგიკეთებია? ან რაიმე ტესტი? მაგარია ბენჩმარეკები ხომ არ გაგიკეთებია? ან რაიმე ტესტი?როგორი ალგორითმია? EMOziko აქ აზრი იმაშია, რომ ახალი რამე მოიგონოს და გამოცდილება შეიძინოს ადამიანმა
არ გამოაქვეყნებ? გაუგზავნე დეველოპერებს და შეავსონ ბიბლიოთეკარა შრიფტებისთვის გაქვს? |
| Posted by: daylight 16 Jun 2014, 22:57 |
| მალე იქნება v2.2................................. |
| Posted by: Detroit 10 Sep 2014, 23:57 |
| საიდან გადმოვწერო ეს, საიტი გათიშულია , ძველი ვერსია არსად დევს? |
| Posted by: Jimran 11 Sep 2014, 01:24 |
| ასსალა̇მ ჺალეჲქუმ გუ̈რჯიჲ! სორრი, ნო უმეუ თოლქო ფო რუსსქი)) Хотел узнать, никто не в курсе , в Мхедрули планируются вводить, чисто для компьютеров и т.д., типа дополнительных знаков как в Латинице: Ä, Ȧ, Á, Ė, Ë, и т.д. И конечно же было бы не плохо, если бы шрифты поддерживали такие буквы как: ჷ, ჴ, ჳ, ჱ, ჺ, ჶ, ჲ * * * Кто знает названия шрифтов Мхедрули, в которых поддерживаются эти буквы(?): ჷ, ჴ, ჳ, ჱ, ჺ, ჶ, ა̇, ჲ Вообще-то мне бы и эти не помешали бы)))): ა̇, ა̈, ე̇, ი̇, ო̇, ო̈, უ̇, უ̈ |
| Posted by: daylight 11 Sep 2014, 13:09 |
| მალე იმუშავებს... დროებით შეგიძლია ისარგებლო: https://drive.google.com/file/d/0B8h3BnFL4od5WURmanpUZzUyTjQ/edit?usp=sharing |
| Posted by: daylight 7 Nov 2014, 23:45 |
| საიტი აღდგენილია................... |
| Posted by: Unknown 26 Dec 2014, 15:59 |
| ხო ხო ხოო რა პრაფესორული ტერმინები და აზრებია დაყრილი ამ თემაში... თქვენ შეგიწუხდათ გული |
| Posted by: maho89 24 Apr 2015, 17:20 |
| 58 გვერდი A4 მაქვს ერთჯერად შესაყვანი.. 85 ლარი რომ არ გადავიხადო არაფერი გამოვა ისე |
| Posted by: შაქროII 25 Apr 2015, 02:07 | ||
Jimran
Titus Cyberbit Basic |
| Posted by: დილა 13 Oct 2016, 07:41 |
| სიახლე ხო არაფერია ამ თემაზე? tesseract -ის ქართულ გაფართოებას ვგულისხმობ. |
| Posted by: EMOziko 13 Oct 2016, 11:36 |
| დილა არის ტესერაქტის ოფიციალურ რეპოში ქართულის ტრეინინგ დეიტა (kat). ასე თუ ისე.კარგად მუშაობს. |
| Posted by: PagSoft 15 Nov 2018, 13:15 |
| ამასობაში SunnyPage 2.8 გამოსულა... |
| Posted by: MONTY 17 Nov 2018, 20:31 |
| ბრაუზერისთვის რო გაკეთდეს ჩანართი კარგი იქნებოდა, არის მასალები რომელიც ფოტოებად არის დასკანირებული და კარგი იქნებოდა მონიშვნისას ტექსტის მიღება კარგი იქნება ნუსხური/ ასომთავრულიდან და მხედრულზე გადამყვანიც https://anbani.ge ს ბრაუზერის ჩანართი და ფოტოებიდან გადამყვანიც ტექსტად |
| Posted by: daylight 28 Dec 2018, 13:39 |
| გამოვიდა ახალი ვერსია SunnyPage v2.9. გამოსწორდა 2013-წლიდან არსებული შეცდომა, რომელიც არ აძლევდა საშუალებას კომპიუტერის კველა ბირთვის გამოყენებას მრავალ გვერდიან დოკუმენტებში. რაც არ აძლევდა უფრო სწრაფად დოკუმენტების დამუშავებას. ასევე გამოსწორდა წინა ვერსიაში არსებული შეცდომა, რომეც არ ქმნიდა გამართულ საძიებო PDF-ს. |
| Posted by: MONTY 28 Feb 2019, 18:16 |
ეს შედეგი მივიღე და დემო ვერსიის შეზღუდვა ხო არ არის ?  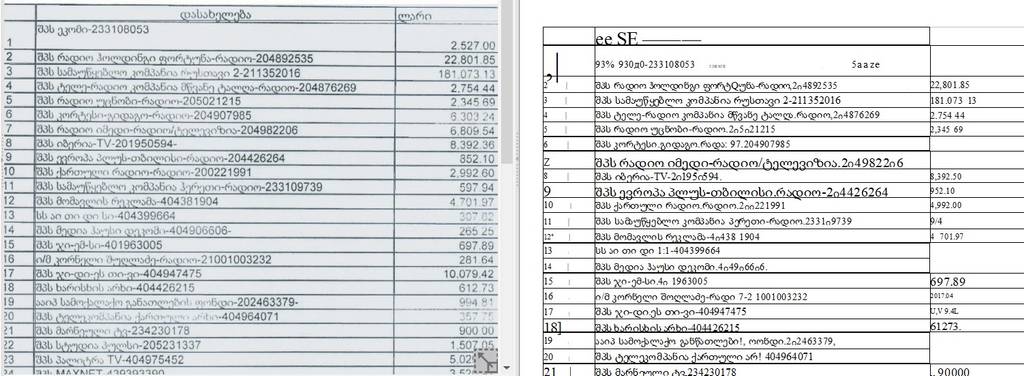 |
| Posted by: t-90 2 Mar 2019, 16:06 |
| MONTY ტესერაქტი ცადე? ----------------- |
| Posted by: MONTY 2 Mar 2019, 19:56 | ||
t-90
არა ეგ არ მიცდია , ესეც ტესერაქტის ძრავზეა მგონი და კარგი შედეგი უნდა ქონოდა მაგრამ რაც ვნახე არ მომეწონა  |
| Posted by: t-90 3 Mar 2019, 06:05 |
| MONTY რავი პროსტო ტესერაქტი ცადე ოღონდ ახალი. მე კმაყოფილი დავრჩი და ნახე აბა შენც. |
| Posted by: 123omari123 3 Mar 2019, 15:20 |
| გამარჯობა ტესერაქტი რამე პროგრამაზე რომ მივაერთო არ ხდება ხომ მასეთი რამე? მაგალითად Adobe Acrobat Pro DC_ზე , როგორც ინგლისურის მხარდაჭერა აქვს ქართულიც რომ ჩავამატო? ერთ GUI_ზე კი გადავიყვანე , მაგრამ წყობას შლის , plain text_ში გადაყავს მაინც ტექსტი. |
| Posted by: decembre 3 Mar 2019, 16:24 |
| მართლა კარგი იქნებოდა ადობემ რომ ჩაამატოს ქართული |
| Posted by: daylight 6 Mar 2019, 14:29 | ||
ოდნავ რომ გაამუქო გამოსახულება უკეთეს შედეგს მიიღებ... |
| Posted by: t-90 6 Mar 2019, 21:31 |
| 123omari123 ტესერაქტს გადაჰქონდა როგორც hocr ფორმატში ისე პლეინ ტექსტში. ამისთვის hocr ფორმატი აწყობს ვინაიდან pdfში გადაიყვანს უპრობლემოდ ან ნუ რავი daylight მცირე მუშაობა უნდა იდეაში იდეაში ნორმალიზება და თრეშჰოლდი ყველაფერს აგვარებს ხოლმე. MONTY მანამდე რამე დამUშავებას აკეთებ სურათებისას? თუ არ აკეთებ მაშინ შემიძლია ცოტა დაგეხმარო. |
| Posted by: 123omari123 7 Mar 2019, 00:12 |
| t-90 ტესერაქტით გადავიყვანე hocr ფორმატში , hocr ფორმატი xml_ში გადავიყვანე (პირდაპირ შევცვალე სახელში გაფართოება), სპეციალური hocr xml_ის გამხსნელიც ვნახე და მხოლოდ ხსნის მეტი არაფერი, მაგრამ pdf_ში გადაყვამყვანი პროგრამა ვერ ვნახე და რამე გზა ხომ არ იცი? |
| Posted by: t-90 7 Mar 2019, 00:27 |
| 123omari123 რა პრობლემაა https://github.com/tmbdev/hocr-tools hocr-pdf ისე უფრო მარტივიც არსებობს ჰტმლით უნდა გახსნა და მერე პდფში დაბეჭდო. |
| Posted by: 123omari123 7 Mar 2019, 00:47 |
| t-90 ესენი ვნახე მაგრამ აზრზე არ ვარ როგორ მოვიხმარო, პითონშია მემგონი გაკეთებული. ვინდოუსი მაქვს. html_ში რომ გავხსენი ტექსტის წყობა არია. ახლა მივხვდი pdf_ს მიწერა ნდომებია ბოლოში  tesseract "imagename.xxx" "outputname" -l kat pdf პ.ს. აქ წერია კარგი რაღაცეები მემგონი, https://stackoverflow.com/questions/28591117/how-do-i-segment-a-document-using-tesseract-then-output-the-resulting-bounding-b |
| Posted by: t-90 7 Mar 2019, 02:01 |
| 123omari123 მოიცა კაცო system-wide დააყენე და ეგაა რა. თუ მაინცდამაინც არ გინდა მაშინ ანაკონდა ჩამოწერე სპეციალურად მაგისთვის და იქ დააყენე. რა პრობლემაა. |
| Posted by: 123omari123 7 Mar 2019, 02:04 |
| t-90 system-wide არ ვიცი რა არის , ზევით ჩავასწორე მივხვდი რაც უნდა მექნა. მემგონი ამაზე კარგი pdf არ გამოვა არსად. |
| Posted by: MONTY 7 Mar 2019, 02:24 | ||
t-90
pdf ში იყო სურათის ფორმატით რამდენიმე გვერდი და სურათის ფორმატში გადავიყვანე nitro თი და სულ ეგ იყო აღარ მინდა რადგან არ იყო ბევრი და ისე ავკრიფე პირველად გამოვიყენე და მეგონა უკეთესი შედეგი ექნებოდა |
| Posted by: t-90 7 Mar 2019, 02:30 | ||
| 123omari123 pip install hocr-tools პითონი გიყენია? MONTY
ნუ თუ კიდე გაგეჩითა და თან ბევრი მომწერე და რამე კაი დასამUშავებელ პროგრამას დაგიწერ. |
| Posted by: MONTY 7 Mar 2019, 04:57 | ||
t-90
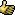 პ.ს ბრაუზერისთვის გააკეთე თუ იცი . ანუ მაგალითად საიტზე სურათის ფორმატით თუ არის ტექსტი , მონიშვნა და შემდეგ ტექსტში გადაყვანა ასევე კაი იქნებოდა ნუსხური/ ასომთავრულიდან და მხედრულზე გადამყვანიც ბრაუზერისთვის (დაახლოებით ისეთი როგორც მონიშნული ტექსტის მთარგმნელი ჩანართებია |
| Posted by: 123omari123 7 Mar 2019, 12:28 |
| t-90 პითონი მემგონი კი მიყენია, მაგრამ მემგონი რაც მინდოდა გავაკეთე, თან ვერ ვერკვევი კარგად ასეთ რაღაცეებში (cmd_ს ვხმარობ ძირითადად დ), მადლობა დახმარებისთვის. pdf_ს დამუშავების პროგრამა თუ ვინმეს უნდა (და უკვე არ იცის) ყველაზე კარგი ჩემი აზრით არის Adobe Acrobat Pro DC, რაც დამჭირვებია ოდესმე ყველა ხელსაწყო არის და მარტივია თან. |
| Posted by: daylight 10 Jun 2019, 13:14 |
| ხელმისაწვდომია SunnyPage 3.0 ვერსია შემდეგ ბმულზე: https://drive.google.com/open?id=1w17nFbB-zlLv6kSm3RN86pAHJubFvcwa |
| Posted by: ლუდოვიკო 10 Jun 2019, 16:51 |
| daylight ლიცენზია უნდა ? |
| Posted by: daylight 10 Jun 2019, 18:58 |
| კი, v2.1-2.9 ვერსიის ლიცენზიასთან თავსებადია... |
| Posted by: almond 12 Jun 2019, 11:43 | ||
|
| Posted by: daylight 28 Aug 2020, 13:43 |
| ხელმისაწვდომია SunnyPage 3.0 ვერსია შემდეგ ბმულზე: https://drive.google.com/file/d/1JhAKHuCAQ9HR4WWZ8wtnru75yTdFVxLj/view?usp=sharing |
| Posted by: koba71786 29 Aug 2020, 18:14 | ||
daylight
სრული ვერსიაა? და ლიცენზია არ უნდა? |
| Posted by: lasha-9 15 Oct 2020, 21:01 |
| http://www.i2ocr.com/free-online-georgian-ocr# |
| Posted by: londre 24 Nov 2020, 10:48 |
| http://www.i2ocr.com/free-online-georgian-ocr# ამ საიტზე ამოცნობილი ტექსტი ვორდში რომ გადამყავს(word2010) რატომღაც არ ექვემდებარება ტექსტის ორივე მხრის სწორხაზოვან გასწორებას. და ადრე ვსარგებლობდი სხვა საიტით http://92.241.95.27/ რომელიც ეხლა არ იხსნება და იქ ესეთი პრობლემა არ იყო და ვინმე თუ ერკვევით გამაგებინეთ |
| Posted by: daylight 9 Mar 2021, 17:34 |
| http://www.sunnypages.eu/index_ka.php გაითვალისწინეთ - დამატებითი ინფორმაციის მისაღებად მიწერეთ ინგლიურად! რადგან მოხდა რებრენდინგი და სხვა კომპანია ახორციელებს გაყიდვებს! |
| Posted by: DMC-12 4 Jul 2023, 15:07 |
| რით განსხვავდება უფასო tesseract-ისგან? ისიც მშვენივრად კითხულობს ქართულს. |