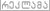არ გამოვრიცხავ, უბრალოდ ვერ ვხდები რა კოდირებაზეა საუბარი.
ეგ PDF კოდირებული ხომ არ ყოფილა? უბრალოდ იყო სურათები, ხომ?
Adobe Acrobat OCR-ს, ეგ სურათები უნდა ამოეცნო და მორჩა, კოდირება რა შუაშია, თავად, Acrobat ხომ არ მოუფიქრებდა ახალ კოდირებას.
თუ შეძლებდა ამოცნობას და მიხვდებოდა რომ რუსული იყო, წესით ავტომატურად რუსულ უნიკოდში ამოიღებდა ტექსტს.
ხოდა, ჩემი ვარაუდია, რომ Acrobat-მა ვერ ამოიცნო ტექსტი,
მაგალითად, ზემოთ რომ სურათი დადე,
http://i65.tinypic.com/rk4iaf.pngპირველი სიტყვა региональные -ს ნაცვლად, Acrobat-მა ამოიცნო реmoHaJibl
ამიტომ, ჯობია უკეთესი OCR სცადო, ყველაზე ცნობილი რუსული პროდუქტი კი სწორედ ეგ Abbyy finereader არის.
რუსულმა პროგრამამ უკეთესად უნდა მოახერხოს რუსულის ამოცნობა, ვიდრე Adobe-მა.